HDFS大規(guī)模數據存儲底層原理詳解 數據處理與存儲服務
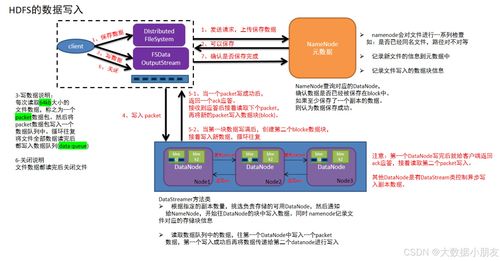
HDFS(Hadoop分布式文件系統(tǒng))是專為大規(guī)模數據處理設計的分布式存儲系統(tǒng)。在數據處理和存儲服務中,HDFS通過其底層架構實現(xiàn)了高吞吐量、高容錯性和可擴展性。
其核心原理包括以下幾個方面:
- 數據分塊與分布存儲:HDFS將大文件分割為固定大小的塊(默認128MB),這些塊被分布存儲在集群的多個數據節(jié)點上。這種機制不僅提高了數據訪問的并行性,還增強了系統(tǒng)的負載均衡能力。
- 主從架構與元數據管理:HDFS采用主從架構,包括一個NameNode(主節(jié)點)和多個DataNode(從節(jié)點)。NameNode負責管理文件系統(tǒng)的命名空間和元數據(如文件塊的位置、權限等),而DataNode負責實際存儲數據塊,并通過心跳機制定期向NameNode匯報狀態(tài)。
- 數據復制與容錯機制:HDFS通過數據塊的副本復制(默認3個副本)來保障數據的可靠性。副本被策略性地分布在不同的機架和節(jié)點上,防止單點故障導致的數據丟失。當某個DataNode失效時,系統(tǒng)會自動從其他副本恢復數據。
- 數據讀寫流程:
- 寫入流程:客戶端向NameNode請求寫入文件,NameNode分配數據塊和DataNode位置,客戶端直接將數據寫入第一個DataNode,并由該節(jié)點負責將數據流水線復制到其他副本節(jié)點。
- 讀取流程:客戶端從NameNode獲取文件塊位置信息,然后直接與相應的DataNode通信讀取數據,實現(xiàn)高吞吐量的數據訪問。
- 數據處理服務集成:HDFS與MapReduce、Spark等計算框架緊密集成,支持數據的本地化處理(數據就近計算),減少網絡傳輸開銷,提升整體數據處理效率。
HDFS的設計充分考慮了大規(guī)模數據場景下的存儲需求,通過分布式、冗余和并行機制,為上層應用提供了穩(wěn)定、高效的數據處理與存儲服務基礎。
如若轉載,請注明出處:http://m.jcwr.com.cn/product/20.html
更新時間:2026-06-19 17:38:07